LLMOps are practices, processes, and infrastructure required to effectively manage, deploy, and maintain LLM applications. LLMOps provides efficient, scalable, and risk-controlled management of LLM applications (essential for effective LLM use).
This article covers the fundamentals of LLMOps, its lifecycle phases, and addresses associated challenges and considerations.
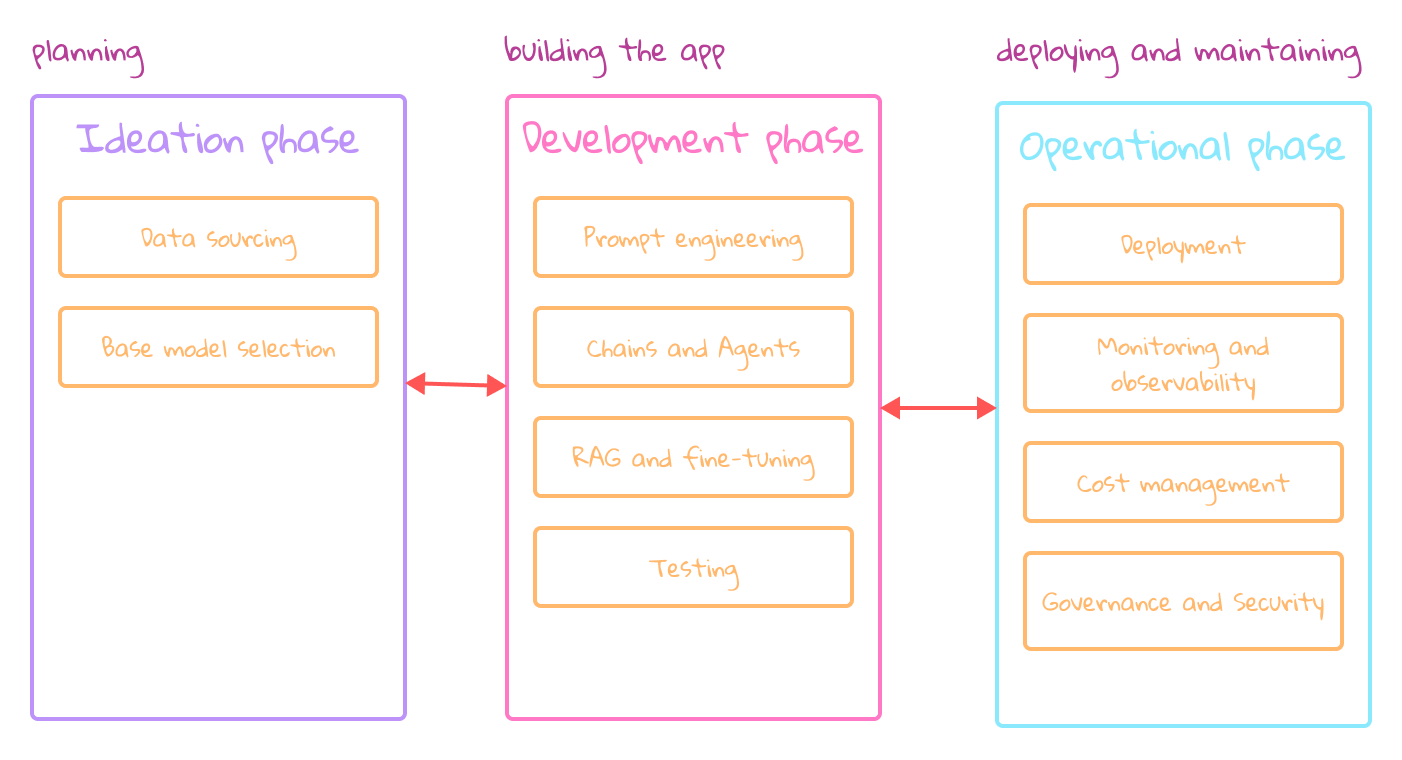
Stages in the lifecycle of LLM applications
Ideation: planning and understanding the business problem, includes:
- Data sourcing: identifying data needs, finding data sources and making them available.
- Base model selection: selecting the right base LLM.
Development: building the app, includes:
- Prompt engineering: crafting effective prompts to ensure the model produces accurate outputs.
- Chains and agents
- RAG and fine-tuning: techniques exist that boost the model’s performance.
- Testing: determining when the application is ready for production.
Operational: deploying and maintaining, includes:
- Deployment: deploying our application to production.
- Monitoring and observability: track of how well everything is working.
- Cost management: handling the expenses associated with using these models.
- Governance and security: access controls and measures to mitigate threats.
|
Ideation phase
Data sourcing
Involves: identifying needs, finding sources, and ensuring accessibility of the data we want to use (providing the latest data). There are three questions will guide us:
i. Is the data relevant?
ii. Is the data available?
- Transform the data to make it ready.
- Set up additional databases
- Evaluating costs
- Consider other access limitations.
iii. Does the data meet standards?
- Concern quality and governance
Base model selection
Most organizations choose pre-trained models, which already have been trained on significant amount of text data. The first step is determining whether to use a proprietary or an open-source model.
Proprietary models
- Advantages: easy of set-up and use, quality assurance, reliability, speed and availability
- Limitations: requires exposing data, customization
Open-source models
- Advantages: in-house hosting, transparency, full customization.
- Limitations: support, commercial use.
Factors in model selection
- Performance: response quality, speed.
- Model characteristics: data use to train the model, context window size, fine-tunability.
- Practical considerations: license, costs, environmental impact
- Secondary factors (often indicators for quality, speed, cost, and power usage): number of parameters, popularity
Development phase
|
Prompt engineering
At the heart of every application is the prompt, which instructs the LLM to generate desired outputs. Prompt engineering enhances prompts in three ways:
- Improve performance
- Control over the output
- Avoid bias and hallucinations
Experiment with:
- LLM settings such as temperature (randomness), or max tokens (output length).
- In-context learning and other prompt design patterns.
A playground environment is useful for trying various models and settings.
Prompt management (tracking results)
- Crucial for efficiency, reproducibility, and collaboration.
- Important to track: prompt, output, model and settings.
- Use prompt manager or version control
- Generating a collection of good input-output pairs for evaluation.
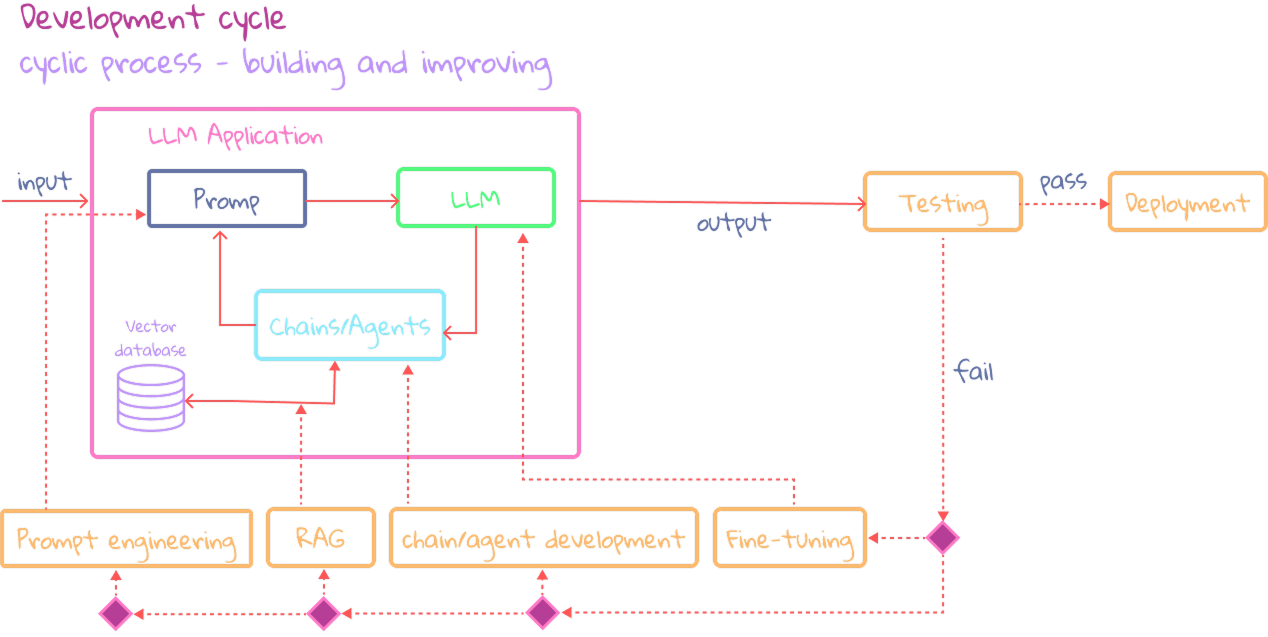
Once we’ve gathered a collection of promising prompts:
- Developing prompt templates
- Templates use placeholders for input and work like recipes for different tasks, fitting any kind of data.
- Essential for making reusable prompts.
Chains and Agents
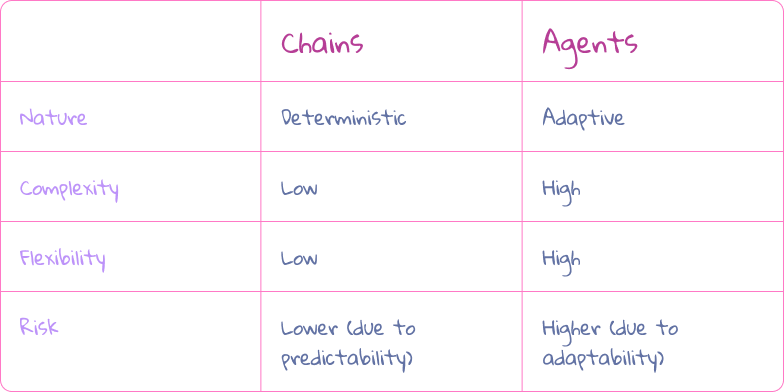
Provide its flow and structure. A chain, pipeline or a flow: connected steps that take inputs and produce outputs.
The need for chains:
- Develop applications that interface with our own systems.
- Establish a modular design, enhancing scalability and operational efficiency.
- Unlock endless possibilities for customization.
Agents
- Follow a design where actions (tools), are available. LLM decides which action to take.
- An action functions as a standalone chain that generates output.
- Unlike deterministic chains, agents are adaptive.
- Useful when:
- There are many actions.
- The optimal sequence of steps is unknown.
- When we’re uncertain about the inputs.
|
RAG and fine-tuning
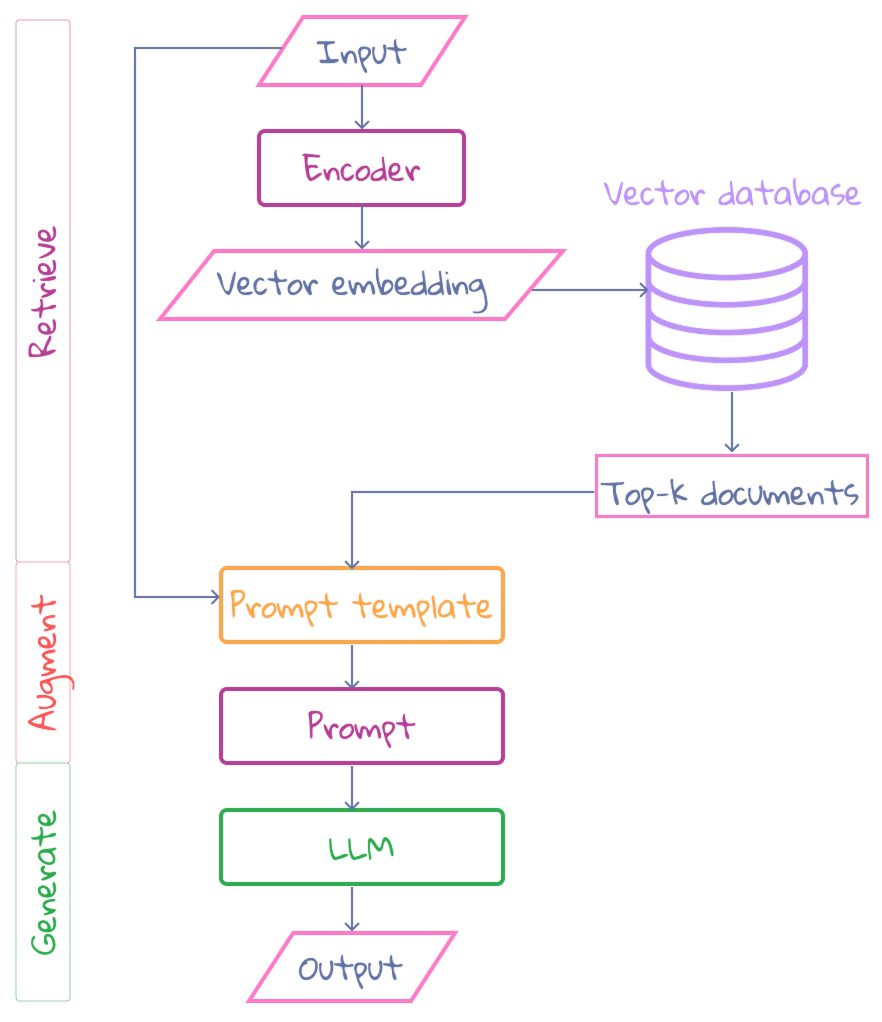
Retrieval Augmented Generation (RAG)
- LLM design pattern, combining reasoning abilities with external knowledge.
- Consists of three steps in a chain (allows use external data):
- Retrieve related documents.
- Augment the prompt with these documents (examples)
- Generate the output.
Retrieve
- Convert the input into a numerical representation (embedding) which captures its meaning. Similar meanings yield similar embeddings. Embeddings are created using pre-trained models.
- Search our vector database: compare the input embedding with those of the documents and calculate their similarity.
- Retrieve the most similar documents.
Augment: Combine input with Top-k documents and create augmented prompt.
Generate: Uses this prompt to create an output.
|
Fine-tuning
- Adjusts the LLM’s weights using our own data.
- Expands reasoning capabilities to specific tasks and domains: different languages or specialized fi
There are two approaches to fine-tuning (different types of data):
- Supervised fine-tuning (transfer learning)
- Demonstration data (input prompts with desired outputs)
- Re-trains parts of the model using this new data
- Reinforcement learning from human feedback
- Requires human-labeled data
- Train an extra reward model to predict output quality
RAG or fine-tuning
RAG
- Use when including factual knowledge.
- ✅ Keeps capabilities of LLM, easy to implement, always up-to-date.
- ❌ Adds extra components, requires careful engineering.
Fine-tuning
- Use when specializing in new domain.
- ✅ Full control and no extra components.
- ❌ Needs labeled data & specialized knowledge, bias amplification, catastrophic forgetting.
Testing
Establishing processes to determine the readiness for the operational phase. It’s crucial because LLMs make mistakes. Vital for assessing the application’s readiness for deployment.
Step 1: Building a test set
- Building the test set was a continuous activity during development but should now be completed.
- Test data must closely resemble real-world scenarios to ensure accurate assessment.
- Various tools, including other LLMs, can help in this process.
Step 2: Choosing our metric
- Scenario 1: There is a correct answer (target label or number)
- Metric Type: Machine Learning Metrics.
- Goal: Assess correctness.
- Examples: Accuracy.
- Scenario 2: No single correct answer, but a reference exists.
- Metric Type: Text Comparison Metrics.
- Goal: Mimic human evaluation of similarity and quality.
- Methods:
- Statistical: Measure overlap between predicted and reference text.
- Model-Based: Use pre-trained models (e.g., LLM-judges) to assess similarity between reference and prediction.
- Scenario 3: No reference answer, but human feedback exists.
- Metric Type: Feedback Score Metrics.
- Options:
- Human Ratings: Humans rate text on quality, relevance, or coherence.
- Model-Based Methods: Models predict expected ratings based on past feedback or verify if feedback was incorpora
- Scenario 4: No reference answer and no human feedback.
- Metric Type: Unsupervised Metrics.
- Goal: Assess text structure and flow.
- Examples: Coherence, fluency, and diversity (measured via statistical or model-based techniques).
Step 3: Define optional secondary metrics
- Output characteristics: bias, toxicity and helpfulness
- Operational characteristics: latency, total incurred cost, and memory usage
Operational phase
Deployment
- Making the application available to a wider audience.
- There’s no one-size-fits-all approach.
- The key factor is the infrastructure we’re planning to use.
- May include: chain/agent logic, a vector DB, LLM, and more.
- Each component needs to be deployed and work together.
Deployment considerations
Step 1: Choice of hosting
- Private/public cloud services, or on-premise hosting
- Many cloud providers offer solutions for hosting and deploying LLMs.
Step 2: API design
- API let different software talk to each other.
- Designing affects scalability, cost, and infrastructure needs.
- Security is crucial, controlled with API keys.
Step 3: How to run
- Options: containers, serverless functions, or cloud managed services.
- Each choice has its advantages and disadvantages, like costs, scalability, efficiency, and flexibility.
CI/CD
Continuous Integration (CI):
- Source: Retrieve source code
- Build: Create a container image containing the code
- Test: Perform integration tests
- Register: Store the container in a registry
Continuous Deployment (CD):
- Retrieve: Retrieve container from registry
- Test: Perform deployment tests
- Deploy: Deploy container to environments: staging or production
Scaling strategies
- Horizontal: adding more machines.
- Vertical: boosting one machine’s power.
Horizontal for traffic, vertical for reliability and speed.
Monitoring and observability
They are often discussed together, but serve distinct roles.
- Monitoring continuously watches a system
- Observability reveals a system’s internal state to external observers.
- To enable observability, we can utilize three primary data sources:
- Logs → detailed chronological event records
- Metrics → quantitative system performance measurements
- Traces → show the flow of requests across system components
Actively monitoring our application: aspects like input, functional, and output monitoring.
Input monitoring
- Monitor input for: tracking changes, errors, or malicious content.
- Data drift is the change in input data distribution over time.
- Addressing data drift requires: monitoring the data distribution, periodically updating the model.
Functional monitoring
- Monitoring an application’s overall health, performance, and stability.
- This encompasses tracking metrics like response time, request volume, downtime, and error rates.
- Chains and agents, it’s important to acknowledge their unpredictable executions and their potential to involve multiple calls to LLMs.
- Monitor system resources: memory and GPU usage, tracking costs.
Output monitoring
- Assessing the responses an application generates to ensure they match the expected content.
- Use metrics defined during testing such as: bias, toxicity, and helpfulness.
- Model drift: when the model gets worse because the relationship between input and output changes → Feedback loops, like refining the application using the latest data, can mitigate this issue.
Alert handling
- Be notified when issues arise.
- Anticipate and prepare for potential problems, threats, and failures by establishing clear procedures.
- Service-level agreements (SLAs) might be in place.
Cost management
- Focusing is on model costs.
- Cost can escalate based on hosting and usage.
Hosting Cost Factors
Self-hosted (open source)
- Cloud: Duration the server remains operational
- On-premise: hardware costs, maintenance and electricity
Externally hosted (proprietary)
- The number of calls or tokens per call
Cost optimization strategies
- Choosing the right model
- Use most cost-effective that still accomplishes the task.
- Use multiple smaller task-specific models.
- For self-hosting, consider model size and reduction techniques.
- Optimizing prompts
- Use automatic prompt compression.
- Content reduction: optimize “chat memory” management or optimize RAG to return fewer results.
- Optimizing the number of calls
- Use batching.
- Use response caching (if applicable).
- Optimize and limits agent calls.
- Set quota and rate limits.
- Consider tasks which don’t require LLM
Governance and Security
Governance involves: policies, guidelines, and frameworks governing LLM applications’ development, deployment, and usage.
Security involves measures to prevent: unauthorized access, data breaches, adversarial attacks or potential misuse or manipulation of the models’ outputs or capabilities.
A wide-spread way to ensure information security and manage access is role-based access control.
- Permissions are assigned to roles
- APIs must adhere to security standards (requests from users with appropriate permission)
- Use a zero trust security model, requiring all users to be authenticated, authorized, and continuously validated
- Ensure the application assumes the correct role when accessing external information.
Common LLM Security Threats
Prompt Injection: Attackers manipulate input fields to execute unauthorized commands, potentially leading to reputation damage or legal issues.
- Mitigation: Treat the LLM as an untrusted user, assume prompt instructions can be overridden, and use tools to identify and block known adversarial prompts.
Output Manipulation: This involves altering the LLM’s output to execute malicious actions in downstream systems on behalf of the user.
- Mitigation: Avoid granting applications unnecessary permissions or authority and implement measures to censor and block undesired outputs.
Denial-of-Service (DoS): Users flood the application with requests, causing performance issues, high costs, and availability failures.
- Mitigation: Implement rate limiting on requests and cap the resource usage allowed per request.
Data Integrity and Poisoning: Malicious or misleading data is injected into training sets, which can occur deliberately or unintentionally (e.g., via copyrighted or personal data).
- Mitigation: Use data from trusted sources, verify legitimacy, employ filters during training to identify poisoned data, and use output censoring.
Protecting
- Use latest security standards and implement mitigation strategies.
- Always assume the perspective of a malicious user targeting our system.
- Stay up to date, see Open Web Application Security Project (OWASP).
LLMOps represents a fundamental shift in how organizations approach AI development. Unlike traditional MLOps, LLM applications require careful attention to prompt engineering, cost management, and security threats unique to language models. Success in this space demands a holistic approach that spans the entire lifecycle — from thoughtful base model selection and data sourcing through continuous monitoring and governance.
The future of LLM applications isn’t just about having access to powerful models; it’s about having the operational excellence to deploy them responsibly and sustainably.
You can find this and other posts on my Medium profile some of my projects on my Github or on my LinkedIn profile.
¡Thank you for reading this article!
If you want to ask me any questions, don't hesitate! My inbox will always be open. Whether you have a question or just want to say hello, I will do my best to answer you!